
Users took the voice-cloning technology to create deepfake audio recordings of the actress Emma Watson reading Mein Kampf by Adolf Hitler and the broadcaster Sir David Attenborough being racist and posted them on the message board 4Chan in the latest abuse of AI technology.
At ValidSoft we decided to test the fake audio recording from Emma Watson to see how effectively our tech would detect the fake.
We used the latest version of our Deepfake detector, and we also used audio from Emma Watson’s genuine audio from her official speech at the UN for her HeForShe campaign to check our results.
While both audio inputs sounded very natural and realistic to the human ear, our forensic examination spotted a clear trend in the deepfake audio that clearly indicated the audio recording was most probably a fake.
This demonstrates that deepfake audio can be convincing to the human ear but because of the decades of experience and research invested in our voice biometric engine and anti-spoof detection capabilities, our technology was able to identify whether the audio was generated by a person or a computer.
To put it simply, without delving into the complex machine learning, AI and DNN techniques utilized by our detector, the red profile of Deepfake audio is distinguishable as synthetic compared to the blue profile of the genuine audio.
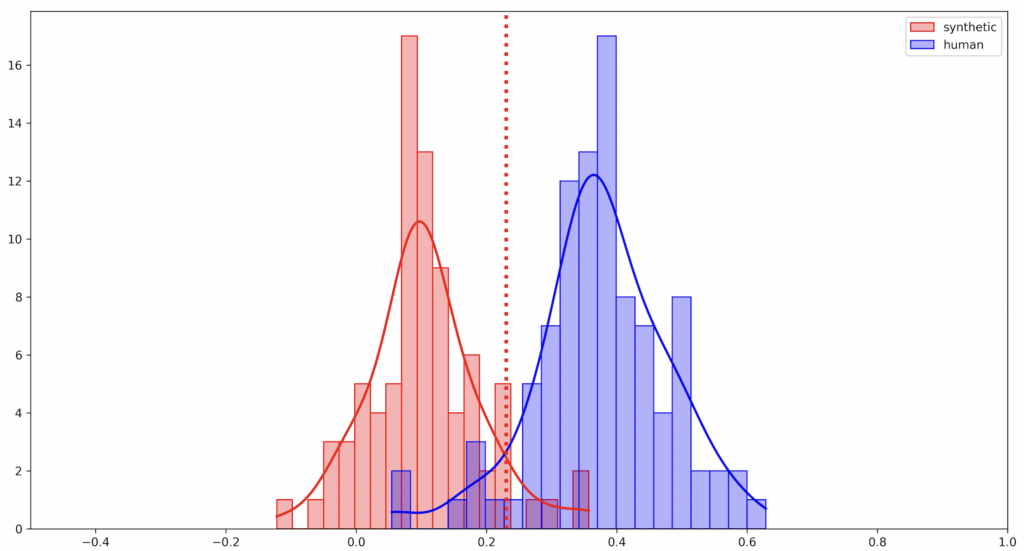
Audio deepfakes potentially pose a significant threat because people often communicate verbally without video — for example, via phone calls, into contact centers, radio, and voice recordings. These voice-only communications greatly expand the possibilities for fraud attacks as well as political propaganda and misinformation applications.
If the digital world is to remain a critical and legitimate resource for information in people’s lives, effective and secure techniques for determining the veracity of an audio source are crucial. How are you safeguarding your digital assets and voice channels from such misuse?


